Big-Data-Analysen werden gerne als Schlüssel für zukünftige Industrie-4.0-Konzepte angesehen. In der Praxis stehen Anwender bei der Umsetzung und Einführung solcher Methoden jedoch vor großen Herausforderungen. Um die Mechanismen, die einer Big-Data-Analyse im Weg stehen, genauer zu untersuchen, führte die Technische Universität München eine Umfrage unter NAMUR-Mitgliedern durch. In der NAMUR (Interessengemeinschaft Automatisierungstechnik der Prozessindustrie) sind derzeit 152 Unternehmen vertreten.
Umsetzung von Datenanalysen läuft schleppend
Rund zwei Drittel der Befragten sind davon überzeugt, dass die Datenanalyse prinzipiell zur Optimierung von Anlagen geeignet ist. An erster Stelle wurde dabei die Unterstützung von Operatoren im laufenden Betrieb genannt, gefolgt von der Diagnose von Prozessen und Komponenten sowie einem verbesserten Verständnis für Zusammenhänge.
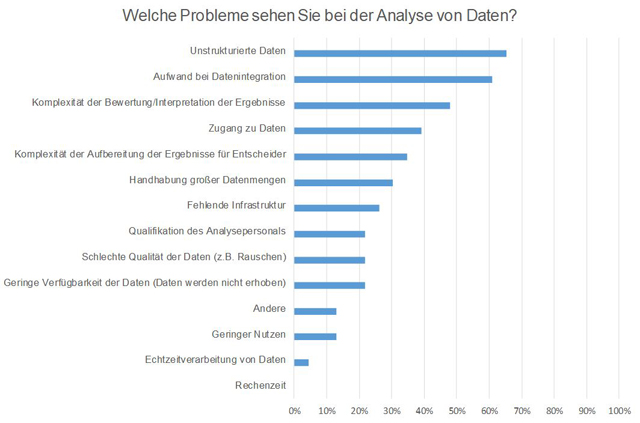
Die Umsetzung verläuft jedoch in den Betrieben eher schleppend. „Unstrukturierte Daten sind das größte Hindernis beim Einsatz von Big Data-Analysen in der Prozessindustrie“, erklärt Prof. Dr.-Ing. Birgit Vogel-Heuser, Leiterin des Lehrstuhls Automatisierung und Informationssysteme an der Technischen Universität München. „Dies bestätigen auch die Ergebnisse unserer Umfrage.“
Messgeräte in chemischen Anlagen produzieren eine Vielzahl an Nutzungs-, Wartungs- und Qualitätsdaten. Diese werden aber meist in verschiedenen Datenbanken gesammelt und selten mit einer synchronen Zeitstempelung versehen. Zusammenhänge sind im Nachhinein schwer auszumachen, bzw. sie müssen für eine Analyse meist händisch zusammengefügt werden.
Dies sind aber nicht die einzigen Herausforderungen. „Weiter wurden in der Umfrage die fehlende Definition eines allgemeinen Datenmodells, die Unterschiedlichkeit der Schnittstellen und der hohe Implementierungsaufwand bemängelt“, so Prof. Vogel-Heuser.
TU München entwickelt skalierbares Integrationskonzept zur Datenaggregation
Um die Herausforderung der unstrukturierten Daten besser zu meistern, entsteht derzeit mit SIDAP ein Skalierbares Integrationskonzept zur Datenaggregation, -analyse, -aufbereitung von großen Datenmengen in der Prozessindustrie. Daran arbeiten Betreiber (Bayer, Covestro, Evonik), Armaturenhersteller (Samson), Feldgerätehersteller (Krohne, Sick), IT-Unternehmen (Gefasoft, IBM) und die Technische Universität München zusammen.
Hierbei sollen aus großen Datenmengen, die u.a. von vorhandenen Messgeräten stammen, neue Zusammenhänge ermittelt werden. Gleichzeitig wird eine datengetriebene sowie serviceorientierte Integrationsarchitektur entwickelt.
„Damit werden Messdaten, Informationen aus der Instandhaltung sowie Daten aus dem Engineering und den Prozessleitsystemen unter Berücksichtigung ihrer unterschiedlichen Semantik in abstrahierter, integrierter und zugriffsgeschützter Form für interaktive Analysen zugänglich“, so Prof. Vogel-Heuser. Erklärtes Ziel ist es, mit aufbereiteten Daten aus heterogenen Quellen die Anlagenverfügbarkeit zu erhöhen, indem Ausfälle vermieden und die Wartung angepasst wird.
Umfrage bei der NAMUR: Big-Data-Analysen scheitern an unstrukturierten Daten
Kategorien: Forschung & Entwicklung | Wirtschaft & Unternehmen
Thema: Digital Business
Autor: Jonas Völker
atp weekly
Der Newsletter der Branche
Das könnte Sie auch interessieren:

Apr
2024
IDTA-Arbeitsgruppe will Digital Twin für Datenräume im Engineering weiterentwickeln
Kategorie: Wirtschaft & Unternehmen
Thema: IDTA: News
Eine IDTA-Arbeitsgruppe von zehn Unternehmen aus der Automatisierung, dem Maschinenbau und der Softwareentwicklung sowie der Industrial Digital Twin Association e.V. (IDTA) hat sich auf der Hannover Messe getroffen, um ...

Apr
2024
KI wird Arbeitswelt laut Bitkom-Studie nachhaltig verändern
Kategorie: Wirtschaft & Unternehmen
Thema: Automatisierungswirtschaft
Die große Mehrheit der Deutschen erwartet, dass Künstliche Intelligenz die Arbeitswelt in den kommenden Jahren verändern wird. So gehen 62 % davon aus, dass sich die Tätigkeiten im Finanzwesen, etwa in Banken, ...

Apr
2024
Siemens eröffnet neues Technology Center auf dem Campus der TU München
Kategorie: Wirtschaft & Unternehmen
Themen: Digital Twin | IoT & IIoT | Robotik
Im neuen Siemens Technology Center (STC) auf dem TUM Campus Garching entwickeln künftig 150 Mitarbeitende und Forschende der Technischen Universität München (TUM) gemeinsam mit Fachleuten von Siemens neue Lösungen ...
Sie möchten das atp magazin testen
Bestellen Sie Ihr kostenloses Probeheft
Überzeugen Sie sich selbst: Gerne senden wir Ihnen das atp magazin kostenlos und unverbindlich zur Probe!

